

The progression of my opinion on AI has been ... elliptical? Not straightforward, we'll say. But as I've gotten to use it more, both at work and through some of my own personal projects, I've started to see where some of the dissonance, I think, lies – both for me and others.
To back it up, I want to talk about software personalization. Since punchcards, people have written new programs because the program they were using had something wrong with it. Did it let you type into the screen and print out what you see? Sure, but we still had Microsft Word. Microsoft Works. Pages. LaTeX. WordPerfect. WordStar. Claris. Lotus. WordPad. TextEdit. Notepad.
Software, at its best, is thinking embodied through code. It should allow you to do whatever you were going to do, but better and faster.
In my past life, when I was the only person who knew how to code in an organization, that was literally my favorite thing about being a software engineer. I could go in, get a problem from someone, help them solve that problem through software and end up feeling like I built something and I helped them. That is literally why I became a software engineer.
And the reason we want to personalize software is because everyone works differently. You cannot just throw a general piece of software at a specific problem and expect it to work. Despite how expensive ERPs like SalesForce, etc., are, every decent-sized implementation requires the end-user to hire a developer to make it work the way they want to.
And they do it because software is expensive! Even buying into fancy, expensive software is cheaper than building in your own.
Or at least, it used to be.
Now, on a personal level, I strive for efficiency. I am unwilling to admin how many e-readers and tablets I have purchased (and re-purchased) to find the, "perfect method for reading." Oh, Kindle won't read epubs. Oh, the Kobo is a pain to sync new files onto if you don't buy them through Kobobooks. Oh, the eInk Android tablet works slower because it's Android trying to run on eInk. Oh, the iPad is too distracting. Oh, the Kindle ...
I don't think the problem is the device or the software. It's my mindset.
And I think everyone's got at least some piece of their life that works that way – or they've gotten lucky enough to find the thing that works for them, and they stick to it. This is why so many people wind up with clothing "uniforms" despite not being mandated. How many people have bough multiples of an item because you don't know if it'll be available the next time you need to get a new one?
And to be honest, that's how I still see most of AI's generative output, at least when it comes to purely creative efforts like writing or other content creation. It's trying to appeal to everyone (becuase it literally is sliced chunks of combined consciousness).
And as an engineer, when I used some of the coding agents from even six months ago, I saw much of the same thing. Sure it could churn out basic code, but when it tried to do anything complex it veered too hard toward the generic, and software engineering is a very precise arena, as anyone who has forgotten to add or remove a crucial semicolon can tell you.
But then at work, we started to get more tools that were a little bit more advanced. They required more planning than when I had been trying to vibe code my way through things. I was surprised at how nuanced the things our new code review tool could catch were, and the complexity of rules and concepts it checked against. And I started to realize that if we were using AI in conjunction with existing tools and putting in the level that I would put into normal engineering, I could start to get some pretty cool stuff.
A quick digression into the past. I previously tried to build my own CMS. I think everyone has at one point. For about the first three or four days, it was an earnest effort: "I'm going to build this and it's going to be the next WordPress."
I quickly realized one of the reasons WordPress sucks so much is it tries to be everything for everyone and therefore it's just winds up being a middling ball of acceptable. (Especially when they got confused as to what they actually wanted to be – a publishing platform or a Substack alternative or a Wix competitor. Gah, no time to fight old battles.) Again, trying to be everything for everyone winds up in the software usually working poorly for every individual.
So I was like, I'm going to build my own CMS. And I built it. And what it ultimately wound up being was an object lesson in why frameworks (e.g., Laravel) tend to be structured the way they are. It was super useful for me as an engineer because I got to see the process of building this large piece of software and think about things like modularity, how to enable plugins you can easily fit into to an existing system. Legendarily helpful for me from a learning-how-to-architect standpoint.
But from an actual usability standpoint, I hated it. Absolutely abhorred using the software.
I spent about 14 hours yesterday of intensely planned vibe-coding. I had my old blog, which was built on Statamic, so I had an existing content structure that Claude could work on.
And I walked that AI through half a day of building exactly the content management system that I want, both for my personal note storage and this blog (which is actually now powered by that same CMS). It took me about two hours to replace what I already had, and the rest of the time was spent building features I've been planning in my head for years. And the UX is surprisingly polished (and weird) because I want it to be polished and weird. It is customized software, fit for exactly my use case.
Originally I thought, "I'm going to build this thing and I'm going to let everybody use it, whoever wants to use it." But as I kept blowing through features I've been salivating over, I realized: I don't think anyone else would want to use this. They would say, "Hey, those are some cool ideas, but I would love it if it did this." And I have absolutely no interest in sitting through and helping somebody else work out how to make their version of this thing – unless they're going to pay me for it as a job, of course.
In an abrupt change for myself, I am now willing to vocally get behind that idea that AI can be used to build good software. But I am going to be adamant about that crucial "used to build" phrasing: I do not believe AI can build good software on its own. I think it can be used as a tool: Software engineers can use AI to build exactly the software we wanted.
None of the stuff it did was beyond my technical capabilities, it merely exceeded my temporal capacity: Stuff I didn't have time to do.
What's especially funny to me is that the best analogy I have for the utility of AI (and this may just be a function of my career history as an engineer): It is a low-code coding tool for software engineers.
We did it, everybody! We finally managed to build a no-code tool, but it's still only functionally usable by engineers.



 AI reporting
AI reporting
If AI-written stories were any good, they’d put them on beats they perceive people care about. Instead, they dump it on topics the suits perceive as lower interest and low-impact, like women’s sports.
Like many, I get annoyed by subscription pricing that doesn’t accurately reflect my needs. I don’t want to spend $5 a month for a color picker app. I don’t really want to spend $4/month on ControlD for ad-blocking and custom internal DNS hosting, and NextDNS is worth $20/year until I hit the five or six times a month it’s completely unresponsive and kills all my internet connectivity.
(I recognize I departed from the mainstream on the specifics there, but my point is still valid.)
I’ve self-hosted this blog and several other websites for more than a decade now; not only is it a way to keep up my Linux/sysadmin chops, it’s also freeing on a personal level to know I have control and important to me on a philosophical level to not be dependent on corporations where possible, as I’ve grown increasingly wary of any company’s motivations the older I get.
So I started looking at options that might take care of it, and over the last few months I’ve really started to replace things that would have previously been a couple bucks a month with a VPS running four such services for $40 a year.
Quick aside: I use RackNerd for all my hosting now, and they have been rock-solid and steady in the time I’ve been with them (coming up on a year now). Their New Year’s Deals are still valid, so you can pay $37.88 for a VPS with 4GB of RAM for a year. Neither of those links are affiliate links, by the way - they’re just a good company with good deals, and I have no problem promoting them.
AdGuard Home - Ad-blocking, custom DNS. I run a bunch of stuff on my homelab that I don’t want exposed to the internet, but I still want HTTPS certificates for. I have a script that grabs a wildcard SSL certificate for the domain that I automatically push to my non-public servers. I use Tailscale to keep all my devices (servers, phones, tablets, computers) on the same VPN. Tailscale’s DNS is set to my AdGuard IP, and AdGuard manages my custom DNS with DNS rewrites.
This has the advantages of a) not requiring to me to set the DNS manually for every wireless network on iOS (which is absolutely a bonkers way to set DNS, Apple), b) keeping all my machines accessible as long as I have internet, and c) allowing me to use the internal Tailscale IP addresses as the AdGuard DNS whitelist so I can keep out all the random inquiries from Chinese and Russian IPs.
The one downside is it requires Tailscale for infrastructure, but Tailscale has been consistently good and generous with its free tier, and if it ever changes, there are free (open-source, self-hosted) alternatives.
MachForm - Not free, not open-source, but the most reliable form self-hosting I’ve found that doesn’t require an absurd number of hoops. I tried both HeyForm and FormBricks before going back to the classic goodness. If I ever care enough, I’ll write a modern-looking frontend theme for it, but as of now it does everything I ask of it. (If I ever get FU money, I’ll rewrite it completely, but I don’t see that happening.)
Soketi - A drop-in Pusher replacement. Holy hell was it annoying to get set up with multiple apps in the same instance, but now I have a much more scalable WebSockets server without arbitrary message/concurrent user limits.
Nitter - I don’t like Twitter, I don’t use Twitter, but some people do and I get links that I probably need to see (usually related to work/dev, but sometimes politics and news). Instead of giving a dime to Elon, Nitter acts as a proxy to display it (especially useful with threads, of which you only see one tweet at a time on Twitter without logging in). You do need to create a Twitter account to use it, but I’m not giving him any pageviews/advertising and I’m only using it when I have to. When Nitter stops working, I’ll probably just block Twitter altogether.
Freescout - My wife and I used Helpscout to run our consulting business for years until they decided to up their subscription pricing by nearly double what we used to pay. Helpscout was useful, but not that useful. We tried to going to regular Gmail and some third-party plugins, but eventually just went with a shared email account until we found Freescout. It works wonderfully, and we paid for some of the extensions mostly just to support them. My only annoyance is the mobile app is just this side of unusable, but hard to complain about free (and we do most of our support work on desktop, anyway).
Sendy - Also not free, but does exactly what’s described on the box and was a breeze to set up. Its UI is a little dated, and you’re best served by creating your templates somewhere else and pasting the HTML in to the editor, but it’s a nice little workhorse for a perfectly reasonable price.
Calibre-web - I used to use the desktop version of Calibre, but it was a huge pain to keep running all the time on my main computer and too much of a hassle to manage when it was running on desktop on one of the homelab machines. Calibre web puts all of the stuff I care about from Calibre available in the browser. I actually run 3-4 instances, sorted by genre.
Tube Archivist - I pay for YouTube premium, but I don’t trust that everything will always be available. I selectively add videos to a certain playlist, then have Tube Archivist download them if I ever want to check them out later.
Plex - I have an extensive downloaded music archive that I listen to using PlexAmp, both on mobile devices and various computers. I don’t love Plex’s overall model, but I’ve yet to find an alternative that allows for good management of mobile downloads (I don’t want to stream everything all the time, Roon).
OK, we need to talk about OREOs ... and how they impacted my view of product iteration.
(Sometimes I hate being a software developer.)

I'm sure you've seen the Cambrian explosion of Oreo flavors, the outer limits of which were brought home to me with Space Dunks - combining Oreos with Pop Rocks. (And yes, your mouth does fizz after eating them.)
Putting aside the wisdom or sanity of whoever dreamt up the idea in the first place, it's clear that Oreo is innovating on its tried-and-true concept – but doing so without killing off its premier product. There is certainly some cannibalization of sales going on, but ultimately it doesn't matter to Nabisco because a) regular Oreos are popular enough that you'll never kill them off completely, and b) halo effect (your mom might really love PB oreos but your kid hates them, so you now you buy two bags instead of one!)
In software, we're taught that the innovator's dilemma tends to occur when you're unwilling to sacrifice your big moneymaker in favor of something new, and someone else without that baggage comes along eats your cookies/lunch.
Why can't you do both?
There are a number of different strategies you could employ, from a backend-compatible but disparate frontend offering (maybe with fewer features at a cheaper cost, or radically new UX). What about a faux startup with a small team and resources who can iterate on new ideas until they find what the market wants?
But the basic idea remains the same: Keep working away at the product that's keeping you in the black, but don't exclude experimentation and trying new approaches from your toolkit. Worst-case scenario, you still have the old workhorse powering through. In most cases, you'll have some tepid-to-mild hits that diversify your revenue stream (and potentially eat at the profit margins of your competitors) and open new opportunities for growth.
And every once in a while you'll strike gold, with a brand-new product that people love and might even supplant your tried-and-true Ol' Faithful.
The trick then is to not stop the ride, and keep rolling that innovation payoff over into the next new idea.
Just maybe leave Pop Rocks out of it.
I had the Platonic ideal of peanut butter pies at my wife's graduate school graduation in Hershey, PA, like five years ago. (They were legit Reese's Peanut Butter Pies from Mr. Reese himself.) I've chased that high for years, but never found it again. The peanut butter pie Oreos were probably the closest I've gotten.
Honestly, I thought we were past this as an industry? But my experience at Developer Week 2024 showed me there's still a long way to go to overcoming sexism in tech.
And it came from the source I least expected; literally people who were at the conference trying to convince others to buy their product. People for whom connecting and educating is literally their job.
Time and again, both I (an engineer) and my nonbinary wife (a business analyst, at a different organization) found that the majority of the masculine-presenting folks at the booths on the expo floor were dismissive and disinterested, and usually patronizing.
It was especially ironic given one of the predominant themes of the conference was developer experience, and focusing on developer productivity. One of the key tenets of dx is listening to what developers have to say. These orgs failed. Horribly.
My wife even got asked when "your husband" would be stopping by.
I had thought it would go without saying, but female- and androgynous-presenting folk are both decision-makers in their own right as well as people with influence in companies large and small.
To organizations: Continuing to hire people who make sexist (and, frankly, stupid) judgments about who is worth talking to and what you should be conversing with them about is not only insulting, it's bad business. Founders: If you're the ones at your booth, educate yourselves. Fast.
I can tell you there are at least three different vendors who were providing services in areas we have professional needs around who absolutely will not get any consideration, simply because we don't want to deal with people like that. I don't assume the whole organization holds the same opinions as their representative; however, I can tell for a fact that such views are not disqualifying by that organization, and so I have no interest in dealing with them further.
Rather than call out the shitty orgs, I instead want to call out the orgs whose reps were engaging, knowledgable and overall pleasant to deal with. Both because those who do it right should be celebrated, and because in an attention economy any given (even negative) is unfortunately an overall net positive.
The guys at Convex**** were great, answering all my questions about their seemingly very solid and robust Typescript backend platform.
The folks at Umbraco**** gave great conference talks, plied attendees with cookies and talked with us at length about their platform and how we might use it. Even though I dislike dotNet, we are very interested in looking at them for our next CMS project.
The developer advocates at Couchbase**** were lovely and engaging, even if I disagree with Couchbase's overall stance on their ability to implement ACID.
The folks at the Incident.io**** booth were wonderful, and a good template for orgs trying to sell services: They brought along an engineering manager who uses their services, and could speak specifically to how to use them.
I want to give a shout-out to those folks, and to exhort organizations to do better in training those you put out as the voice of your brand. This is not hard. And it only benefits you to do so.
Also, the sheer number of static code analysis companies makes me thinks there's a consolidation incoming. Not a single one of three could differentiate their offerings on more than name and price.
“[Random AI] defines ...” has already started to replace “Webster’s defines ...” as the worst lede for stories and presentations.
I let the AI interview in the playbill slide because the play was about AI, but otherwise, no bueno.

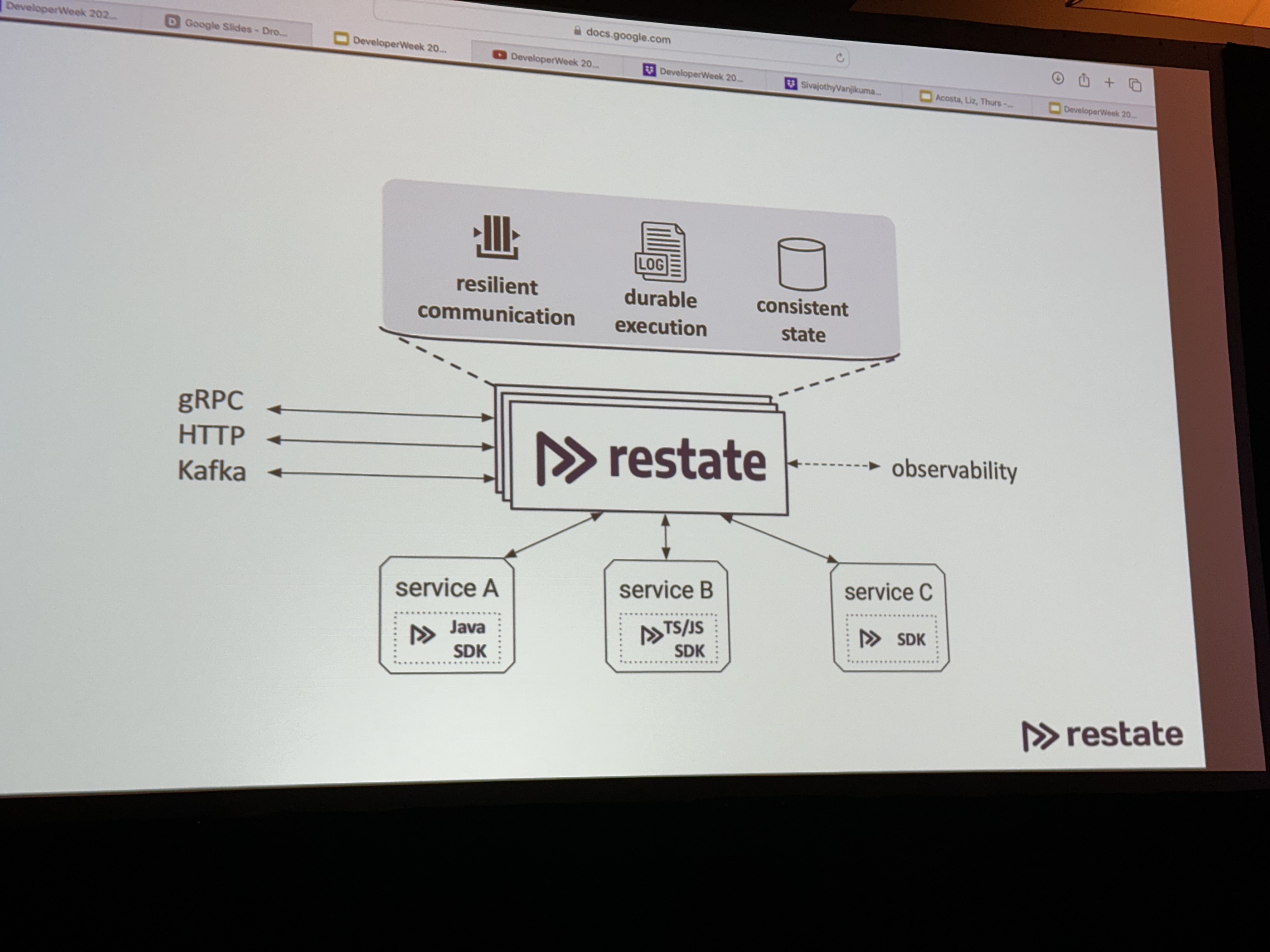
The way to guarantee durability and failure recovery in serverless orchestration and coordination is … a server and database in the middle of your microservices.
I’m sure it’s a great product, but come on.
The way to guarantee durability and failure recovery in serverless orchestration and coordination is … a server and database in the middle of your microservices.
I’m sure it’s a great product, but come on.

Lacking vision
It is incredible that all of this works with just a single button click, but all that scaling complication also explains the bad news: you can only have a single Mac display in visionOS. You can’t have multiple Mac monitors floating in space. Maybe next time.
Re: Apple’s convoluted EU policies
It's surprising how often D&D is relevant in my everyday life. Most people who play D&D are in it to have fun. They follow the rule - not just the letter of the law, but the spirit.
But every once in a while you'll encounter a "rules lawyer," a player who's more concerned with making sure you observe and obey every tiny rule, punish every pecadillo, than actually having fun.
All the worse when it's your GM, the person in charge of running the game.
But there's one thing you learn quickly - if someone is trying to game the rules, the only way to win (or have any fun) is play the game right back.
For smaller/mid-tier devs, if you're only offering free apps you should probably just continue in the App Store.
But for larger devs who might run afoul of the new guidelines where apps distributed outside the App Store get charged a fee every time they go over a million users?
Oops, Apple just created collectible apps, where if you have Facebook (and not Facebook2), we know you got in early. Think about it: Same codebase, different appId. The external app stores can even set up mechanisms for this to work - every time you hit 999,000 installs, it creates a new listing that just waits for you to upload the new binary (and switches when you hit 995K). Now your users are incentivized to download your app early, in case becomes the big thing. Lower app # is the new low user ID.
If I'm Microsoft, I'm putting a stunted version of my app in the App Store (maybe an Office Documents Viewer?) for free, with links telling them if they want to edit they have go to the Microsoft App Store to download the app where Apple doesn't get a dime (especially if Microsoft uses the above trick to roll over the app every 995K users).
Even in the world where (as I think is the case in this one) Apple says all your apps have to be on the same licensing terms (so you can't have some App Store and some off-App Store), it costs barely anything to create a new LLC (and certainly less than the 500K it would cost if your app hits a million users). Apple's an Irish company, remember? So one of your LLCs is App Store, and the other is external.
To be clear, I don't like this setup. I think the iPhone should just allow sideloading, period. Is all of this more complicated for developers? Absolutely! Is the minimal amount of hassle worth saving at least 30% percent of your current revenue (or minimum $500K if you go off-App Store)? For dev shops of a certain size, I would certainly think so.
The only way to have fun with a rules lawyer is to get them to relax, or get them to leave the group. You have to band together to make them see the error of their ways, or convince them it's so much trouble it's not worth bothering to argue anymore.
Yes, Apple is going to (rules-)lawyer this, but they made it so convoluted I would be surprised if they didn't leave some giant loopholes, and attempting to close them is going to bring the EU down on them hard. If the EU is even going to allow this in the first place.

VCR as HDD
The details of a Russian expansion card from the 90s that allowed you to use a VHS tape as a storage medium.
We randomly went on a rabbit hole last week in the car about how VHS and VCRs actually work - incredible technology.

Fear of AI is eternal
“The big curiosity is what medium a Furby uses to record audio,” one employee wrote. “I would assume that since it can ‘respond’ to certain audio cues that it would use storage similar to a digital answering machine or straight computer memory chips. Anybody know?”
Others said “Furby is only a $35 toy and is not that sophisticated. As a previous [listserv] posting pointed out, the ‘learning’ the doll does is programmed into it so that the longer you use it the more it ‘knows.’”
A great reading of newly FOIA'd documents from the folks at 404 Media. I definitely understand the impetus to understate existing rules about banning personal electronics from NSA spaces, but doesn't it also smack somewhat of security by obscurity?
It's always fun to get messages worrying about people FOIA'ing documents in documents you FOIA'ed.
I'll be hitting the lecture circuit again this year, with three conferences planned for the first of 2024.
In February, I'll be at Developer Week in Oakland (and online!), talking about Data Transfer Objects.
In March, I'll be in Michigan for the Michigan Technology Conference, speaking about clean code as well as measuring and managing productivity for dev teams.
And in April I'll be in Chicago at php[tek] to talk about laws/regulations for developers and DTOs (again).
Hope to see you there!
Who holds a conference in the upper Midwest in March???

A Vision for the future
Apple keeps emphasizing that the Vision Pro isn’t meant to isolate you from the rest of the world, and the display on the front of the headset is designed to keep you connected to others.
I don't care if it isolates me? I don't want to be wearing it constantly, anyway.
If I'm perfectly honest, the killer VR app for me is working. If I can use a head-mounted display for a large screen for an existing computer (and get rid of the gigantic monitors of my workstation / use them when working away from home), I'm in.
Just ... not for $3.5K.
I mean, I would also probably play games on it, but not dramatically more than I do now (which is maybe 1-2 hours a week across all platforms, if I'm lucky?)


Number Go Up
by Zeke Faux
Highly Recommended
A good deep-dive into the crypto world. Faux does a great job of explaining how crypto (doesn't) work, and the various frauds/scams. Definitely the best book-length treatment currently out there, and an excellent gateway drug to Web3 Is Going Just Great.
Give the Lewis book the widest possible berth. That man legitimately thinks that his simplified narrative version of SBF perfectly encompasses how SBF’s actual human brain works. He also seemed unable to comprehend that SBF was straight up lying to him at points while also lying by omission. Simply wild ironclad belief in one’s own power of perception. Hard pass.
Hey everybody, in case you wanted to see my face in person, I will be speaking at LonghornPHP, which is in Austin from Nov. 2-4. I've got two three things to say there! That's twice thrice as many things as one thing! (I added a last-minute accessibility update).
In case you missed it, I said stuff earlier this year at SparkConf in Chicago!
I said stuff about regulations (HIPAA, FERPA, GDPR, all the good ones) at the beginning of this year. This one is available online, because it was only ever available online:
I am sorry for talking so fast in that one, I definitely tried to cover more than I should have. Oops!
The SparkConf talks are unfortunately not online yet (for reasons), and I'm doubtful they ever will be.
Block themes parsing shortcodes in user generated data; thanks to Liam Gladdy of WP Engine for reporting this issue
As a reminder, from Semver.org:
Given a version number MAJOR.MINOR.PATCH, increment the: 1. MAJOR version when you make incompatible API changes 2. MINOR version when you add functionality in a backward compatible manner 3. PATCH version when you make backward compatible bug fixes
As it turns out, just because you label it as a "security" patch doesn't make it OK to completely annihilate functionality that numerous themes depend on.
This bit us on a number of legacy sites that depend entirely on shortcode parsing for functionality. Because it's a basic feature. We sanitize ACTUAL user-generated content, but the CMS considers all database content to be "user content."
WordPress is not stable, should not be considered to be an enterprise-caliber CMS, and should only be run on WordPress.com using WordPress.com approved themes. Dictator for life Matt Mullenweg has pretty explicitly stated he considers WordPress' competitors to be SquareSpace and Wix. Listen to him.
Friends don't let their friends use WordPress
I have used WordPress for well over a decade now, for both personal and professional projects. WordPress was how I learned to be a programmer, starting with small modifications to themes and progressing to writing my own from scratch. The CMS seemed to find a delicate balance between being easy to use for those who weren't particularly technically proficient (allowing for plugins that could add nearly anything imaginable), while also allowing the more developer-minded to get in and mess with whatever they wanted.
I would go as far as to call myself a proselytizer, for a time. I fought strenuously to use it at work, constantly having to overcome the "but it's open-source and therefore insecure!" argument that every enterprise IT person has tried for the past two decades. But I fought for it because a) I knew it, so I could get things done more quickly using it, and b) it did everything we wanted it to at no cost. Who could argue against that?
The problems first started around the WordPress API. Despite an upswell of support among developers, there was active pushback by Matt Mullenweg, in particular, about including it in Core and making it more widely available - especially confusing since it wouldn't affect any users except those that wanted to use it.
We got past it (and got the API into core, where it has been [ab]used by Automattic), but it left a sour taste in my mouth. WordPress development was supposed to be community-driven, and indeed though it likely would not exist in its current state without Automattic's help, neither would Automattic have been able to do it all on its own. But the community was shut out of the decision-making process, a feeling we would get increasingly familiar with. Completely blowing the up the text editor in favor Gutenberg, ignoring accessibility concerns until an outside third-party paid for a review ... these are not actions of product that is being inculcated by its community. It's indicative of a decision-making process that has a specific strategy behind it (chasing new users at the expense of existing users and developers).
Gutenberg marked the beginning of the end for me, but I felt the final break somewhere in the 5.x.x release cycle when I had to fix yet another breaking change that was adding a new feature that I absolutely did not need or want. I realized I was not only installing plugins were actively trying to keep changes at bay, I was now spending additional development time just to make sure that existing features kept working. It crystallized my biggest problem I'd been feeling: WordPress is no longer a stable platform. I don't need new; I can build new. I need things to keep working once they're built. WordPress no longer provides that.
And that's fine! I am not making the argument that Automattic should do anything other than pursue their product strategy. I am not, however, in their target market, so I'm going to stop trying to force it.
A farewell to a CMS that taught me how to program, and eventually how to know when it's time to move on.
As a person whose life is consumed by the digital world, this feels an exceptionally strange piece to write. I spend the vast majority of my day on a device, whether that’s a computer for work (I’m a web developer, no escaping it) or a phone/computer/tablet for whatever (likely cat-related) thing I happen to be internetting in my free time.
So you can understand my internal consternation when confronted with a situation that makes me lean toward limiting technology. I’m more than a little worried about technology, both for the reaction it’s drawing as well as its actual impact it’s having on society as a whole — and not just because three out of every four stories on every single news site is about Pokemon Go.
But we’ll get there. First, let’s start with something more mainstream.
Technology (and, more specifically, apps/the internet) are famous for disruption. Tesla’s disrupting the auto industry. So’s Uber. AirBnB “disrupted” the hotel industry by allowing people to rent out rooms (or entire houses) to perfect strangers. The disruption in question (for hotels) was that they no longer were the combination of easiest/cheapest way to stay in a place away from home. But there was also “disruption” in terms of laws/regulation, a fight AirBnB is currently waging in several different locations.
Some of these fights revolve around leases — many landlords do not allow subleasing, which is what some people do on AirBnB: Rent out a space they rent from someone else for a period of time. AirBnB asks that people confirm they have the legal right to rent out the space they’re listing, but there’s no enforcement or verification of any kind on AirBnB’s part. AirBnB thus, at least in some non-small number of cases, is profiting off of at best a breach of contract, if not outright illegality. Then there’s the fact that anyone, be they murderer, sex offender or what have you, can rent out their space and the person renting the room may be none the wiser.
And maybe these things are OK! Maybe it should be caveat emptor, and the people who ultimately lose out (the actual lessees) are the ones primarily being harmed. But that ignores the people who were just trying to rent from AirBnB and had to deal with an irate landowner, or the property owner who has to deal with the fallout/repercussions of the person breaking the lease.
The clichéd technical model of “move fast and break things” should have some limits, and situations where people are dying need more foresight than “we’ll figure it out as we go along.” Otherwise, how do we determine the appropriate death toll for a new tech service before it needs to ask permission rather than forgiveness? And before you dismiss that question as overbearing/hysterical, remember that actual human beings have already died.
But not everything is so doom and gloom! Why, Pokemon Go is bringing nerds outside, causing people to congregate and interact with one another. It’s legitimately fun! Finally my inner 10-year-old can traipse around the park looking for wild Pikachu to capture. Using augmented reality, the game takes your physical location and overlays the game on top of it. As you walk around with your phone, it uses your GPS location to pop up various Pokemon for you to capture. There are also Pokestops, which are preset locations that provide you with in-game items, located in numerous places (usually around monuments and “places of cultural interest”). There are also gyms in similarly “random” places where you can battle your Pokemon to control the gym.
And no deaths! (Yet, probably.) But just because no one is dying doesn’t mean there aren’t still problems. Taste-wise, what about the Pokestop at Ground Zero (or this list of weird stops)? Business-wise, what about the Pokestop near my house that’s in a funeral home parking lot? You legally can’t go there after-hours … but Pokemon Go itself says that some Pokemon only come out at night. What happens during a funeral? There’s no place where businesses can go to ask to be removed as a Pokestop (and frankly, I can imagine places like comic book stores and such that would pay for the privilege). And who has the right to ask that the 9/11 Memorial Pool be removed? Victims’ families? There’s an appropriation of physical space going on that’s not being addressed with the seriousness it should. Just because in the Pokemon game world you can catch Pokemon anywhere doesn’t mean, for example, that you should necessarily allow have them popping up at the Holocaust Museum.
I would like to preempt arguments about “it’s just an algorithm” or “we crowd-sourced” the information by pointing out that those things are useful in their way, but they are not excuses nor are they reasons. If you decide to crowd-source information, you’d better make sure that the information you’re looking for has the right level of impact (such as the names of boats, or in Pokemon Go’s case, the locations of Pokestops). Some of these things can be fixed after the fact, some of them require you to put systems in place to prevent problems from ever occurring.
In this case, you can cast blame on the players for not respecting the law/common sense/decency, and while you’d be right, it shifts the blame away from the companies that are making money off this. What inherent right do companies have to induce people to trespass? Going further, for some reason doing something on “the internet” suddenly cedes rights completely unthinkable in any other context. Remember the “Yelp for people” that was all but an app designed to encourage libel, or the geo-mapping firm that set the default location for any IP address in the US to some Kansan’s front yard. These were not malicious, or even intentional acts. But they had very real affects on people that took far too long to solve, all because the companies in question didn’t bother (or didn’t care) about the real effects of their decisions.
At some point, there’s at the very least a moral — and should be legal, though I’m not necessarily advocating for strict liability — compulsion to consider and fix problems before they happen, rather than waiting until it’s too late. The proper standard probably lies somewhere around where journalists have to consider libel — journalists have a responsibility to only report things they reasonably believe to be accurate. Deadlines and amount of work are not defenses, meaning that the truth must take priority over all. For places where the internet intersects with the real world (which is increasingly becoming “most internet things”), perhaps a similar standard that defers to the reasonably foreseeable potential negative impact should apply.
Technology is only going to grow ever-more entrenched in our lives, and as its function moves closer to an appendage and away from external utility, it’s incumbent upon actors (both governmental and corporate) to consider the very real effects of their products. It (here meaning “life,” “work” or any number of quasi-existential crises) has to be about more than just making money, or the newest thing.
One of my pet peeves is when people/corporations speak as there's a legal right to a use a given business model. "Well, if it were illegal to train AIs on copyrighted material, we wouldn't be able to afford to do it!" Yes ... and?
I like technology. I think this is fairly obvious. I like it personally because it removes a lot of friction points in my life (some in ways that other people appreciate as more convenient, some in ways that are convenient only to me). But the downside of technology is that businesses use it as a way of not paying people for things that actually often do require human judgment.
The proper way most systems should be set up for, say, a medical insurance claim is that you fill out everything electronically so the data is in the right place and then an actual human can make an actual human judgment on your case. In practice, however, you fill out the form and the information whisks away to be judged by a computer using a predetermined set of rules.
If you're very, very lucky, there might be a way for you to appeal the computer's ruling to a human being (regardless of outcome/reason) — but even then, that person's power is often limited to saying, "well, the computer said you don't pass."
The following story is by no means of any actual consequence, but does serve as a prime example of how to waste your money employing customer service people. I recently switched banks. When I was at the branch doing so, I asked out of curiosity if they allow custom debit cards (my girlfriend has a credit card that looks like a cassette tape, and is always getting compliments on it. I'm petty and jealous, so I want a cool card, too).
Finding out the answer is yes, I waited until my actual debit card came so I can see the pure eye-rending horror that is their color scheme before sitting down and trying to make my own. I wasn't really looking to lose a good portion of my day to this endeavor, so I used the Designer's Prerogative to begin.
{kind=link}
I wanted something computer-y (see above, re: my opinion on technology), so I started with this (royalty-free) stock image. Their design requirements say the PeoplesBank logo has to be large and colored (dark red for Peoples, gray for Bank), so I swapped the colors on the image and flipped it so the faux-binary wouldn't be covered by the big VISA logo or hologram (see the image at the top of the post).
It's not a masterpiece, it's not like I slaved over it for hours. It's just a cool design that I thought would work well. Upload, and send!
Three hours later, I got an email: SORRY — your design wasn't approved!
We regret to inform you that the image you uploaded in our card creator service does not meet the guidelines established for this service, so it has not been accepted for processing. Please take a moment to review our image and upload guidelines at www.peoplesbanknet.com and then feel free to submit another image after doing so.
Huh. Well maybe I ran afoul of the design guidelines. Let's see, competitive marks/names, provocative material (I don't think so, but who knows?), branded products ... Nope. The only thing that it could possibly even run afoul of is "Phone numbers (e.g. 800 or 900 numbers) and URL addresses (e.g. www.xyz.com)", but since it's clearly not either of those things, I figured it would be OK.
So I called up PeoplesBank and explained the situation.
"Hi, I was wondering why my custom card design was rejected."
"Well, it should have said in the email why it was rejected."
"Yes, it says 'it does not meet the guidelines established for the service.' I've read the guidelines and there's nothing in there that would preclude this. It's just an abstract image with some binary code, and it's not even real binary, it's just random 1s and 0s."
"Please hold."
[5 minutes pass]
"OK, it says the copyrighted or trademarked material part is what it ran afoul of."
"It's just numbers and an abstract image. How could that be the problem?"
"That's what it says."
"OK, well, is there someone somewhere I can talk to who would be able to tell me what I need to alter in order to make it acceptable?"
"Please hold."
[10 minutes pass]
"OK, you said something about the numbers? Something about by Mary?"
"Yes, it's binary code. Well, it's not even really binary, it's pseudo-binary."
"Well, that's it."
"What's it? It's just random 1s and 0s. It's the equivalent of putting random letters in a row and saying they're words."
"Apparently it's copyrighted."
"... OK, well, is there someone who can tell me what I need to change? Because I doubt that, even if I changed the numbers around and submitted it, it would still go through. I just need to know why it's not going through so I can change it so it does go through."
"Oh, we'll need to research that. Is there a number I can call you back at?"
My best guess is that somehow this is getting tripped up as an allusion or reference to The Matrix by some content identifier program somewhere, which a) it's clearly not, b) The Matrix wasn't actually binary, and c) you can't copyright the idea of code on a screen. The computer identified as such, and since no one actually knows why it thought that, no one can tell me how to fix it.
And since it's such an important business case (not getting sued for copyright infringement, even though there's absolutely no way VISA is getting sued even if someone puts Mickey on their damn credit card), no one is actually empowered to overrule the computer.
What I'll probably end up doing is just trying another image (I was thinking maybe a motherboard) because at this point I've already spent more time than I actually care about the design of my debit card. It's just frustrating.
I sincerely hope I don't have to update this post.
Election night is always tense in a newsroom - even when, as the case with the Pennysylvania governor's race, the outcome isn't in doubt, there are still so many moving parts and so many things that can change. Whether it's a late-reporting county/precinct or trying to design a front page you've been thinking about for weeks, there's always something that can go wrong. That's why, this year, I tried to prep my part of the election coverage with as few manual moving parts as possible. Though (as ever) things did not go according to plan, it definitely provided a glimpse at how things might run — more smoothly — in the future.
I set out in the middle of October with two aspects of the coverage. The first, live election results, was something I've been in charge of since the first election after I arrived at the York Daily Record in 2012. I've always used some combination of Google Docs (the multi-user editing is crucial for this part, since our results are always scattered around various web pages and rarely scrape-able) and PHP to display the results, but this year I had my GElex framework to start from (even if I modified it heavily and now probably need to rewrite it for another release).
The results actually went incredibly smoothly and (as far as I know) encountered no problems. Everything showed up the way it was supposed to, we had no downtime and the interface is as easy I can conceivably make it. You can take a gander at the public-facing page here, and the Sheet itself here. The one big improvement I made this time around was on embeds. Though there's always been the ability to embed the full results (example), this year — thanks to the move to separate sheets per race — it was possible to do so on a race-by-race basis.
This helps especially in consideration with our print flow, which has always been that election stories get written so the exact vote totals can be inserted later via a breakout box. By embedding the vote totals into the story, this meant we didn't have to go back in and manually add them on the web.
The governor's race stole pretty much all the of the headlines (/front pages) in York County owing to its status as Tom Wolf's home county. For us, this meant we'd be doing twice as many live maps as usual. The county-by-county heat map is relatively cliché as political indicators go, but it's still a nice way to visually represent a state's voters.
Since he's a native, we also decided this year to include a map of just York County, coding the various boroughs and townships according to their gubernatorial preferences. My first concern was online — we've done both of those maps in print before, so worse case scenario we'd be coloring them in Illustrator before sending them to press.
I wanted interactivity, fidelity, reusability and (if at all possible) automation in my maps. When it came to reusability and fidelity, SVG emerged as the clear front-runner. It's supported in most major browsers (older flavors of IE excepted, of course), on mobile and scales well.
The other options (Raphael, etc.) locked us down paths I wasn't really comfortable with looking ahead. I don't want to be reliant on Sencha Labs to a) keep developing it and b) keep it free when it comes to things like elections and maps. I would have been perfectly fine with a Fusion Table or the like, but I also wanted to look at something that could be used for things other than geocoded data if the need arose.
Manipulating SVGs isn't terribly difficult ... sometimes. If the SVG code is directly injected into the page (I used PHP includes), it's manipulable using the normal document DOM. If you're including it as an external file (the way most probably would), there are options like JQuery SVG (which hadn't been updated in TWO YEARS until he updated it less than a week before the election, or too late for me to use) or this method (which I was unable to get to work). (Again, I just cheated and put it directly on the page.)
Manipulating fills and strokes with plain colors is fairly easy using jQuery, just change the attributes and include CSS transitions for animations. The problems arises when you try to do patterns, which are much different.
I wrote a tiny jQuery plugin (pluglet?) called SVGLite to assist with this, which you can read more about here. When backfilling older browsers, I figured the easiest thing to do was serve up PNG images of the files as they existed. Using everyone's favorite PHP library for ImageMagick, imagick, this was trivial. Simply running a few PREG_REPLACEs on the SVG file before serving it to Imagick helped me get the colors I needed.
It turns out there aren't a lot of free options for scraping data live, and as I've mentioned before, free is pretty much my budget for these sorts of things. But there is one. Import.io, which has the classic engineer's design problem of making things more difficult by trying to make them easier, turned out to be just what we needed when it came to pulling down governor's data.
Working off the results site for each county, I set up a scraper API that trolled all 67 pages and compiled the data for Wolf and Corbett. This was then downloaded into a JSON file that was served to the live Javascript and PHP/ImageMagick/PNG maps. Given that I didn't want to abuse the election results server (or melt ours), I built a small dashboard that allowed me to control when to re-scrape everything.
{kind=link}
This part actually went almost as well as the live results, with one MASSIVE EXCEPTION I'll get to after the next part. The boroughs/townships data presented its own problems, in the form of only being released by PDF.
Now, running data analysis on a PDF is not terribly difficult — if you're not time-constrained, I'd definitely recommend looking into Tabula, which did an excellent job of parsing my test data tables (2013 elections), as well as the final sheet when it was all said and done.
Unfortunately, processing each one took about 45 minutes, which wasn't really quick enough for what we needed. So we turned to the journalist's Mechanical Turk: freelancers and staff. Thanks to the blood, tears, sweat and math of Sam Dellinger, Kara Eberle and Angie Mason, we were able to convert a static PDF of numbers into this every 20 minutes or so.
It's always a good idea to test your code — and I did. I swear.
My problem did not lie in a lack of testing, but rather a lack of testing using real numbers or real data. For readability purposes, the election results data numbers are formatted with a comma separating every 3 numbers, much in the way numbers always are in non-financial or -computer contexts (e.g., 1,000, 3,334,332).
UNFORTUNATELY, when I did all my testing, none of the numbers I used went above 1,000. Even when I was scraping the test data the counties were putting up to test their election results uploading capabilities, the numbers never went above 500 or so — or, if they did, they were tied (1,300 for Wolf, 1,300 for Corbett).
The problem lies in how the scraper worked. It was pulling all of the data as a string, because it didn't know (or care) that they were votes. Thus, it wasn't 83000, it was '83,000'. That's fine for display purposes, but it's murder on mathematical operations.
About an hour after our first results, the ever-intrepid and knowledgeable Joan Concilio pointed out that my individual county numbers were far too low - like, single or double digits, when the total vote count was somewhere north of 200,000. After walking all of my numbers back to import.io, I realized that I needed to be removing the commas and getting the intVal() (or parseInt(), where appropriate).
(I also originally intended to provide the agate data using the same method, but the time it took to quash the number bug meant it was safer/wiser to go with the AP's data.)
Conclusion:
-
Always test your data.
-
Always make sure your data matches the type you're looking for.
-
Sometimes the overhead of statically typed languages is worth the trouble.
Overall, everything went fairly well, with the exception of the aforementioned bug report (which also made us double- and triple-check the print graphic). The advantage of SVG, aside from its digital flexibility, was that after a quick Save-As and conversion in Illustrator, we had a working print file ready to go.
Another election, in the books.
I thought I was soooo smart linking to everything, except now all the links are dead and useless.